# 본 내용은 " [나도코딩] - 파이썬 활용편(5) 데이터분석 및 시각화 " 강의를 듣고, 복습하고 공부한 내용을 다루었습니다.
오늘 포스팅할 내용은 다음과 같습니다.
Pandas #3. 데이터 확인
05. 데이터 확인
=> 시리즈 형태, 데이터프레임 형태에서 데이터를 확인하고, 데이터 정보를 탐색하는 방법에 대해 학습합니다.
05. 데이터 확인
5-1. 데이터 프레임 확인
먼저 사용할 데이터를 import 시켜줍니다.

데이터 프레임에 대한 정보를 확인하기 위한 방법을 소개해 드리겠습니다.
(1) .describe()
- 계산할 수 있는 데이터에 대해서 칼럼별 통계량을 제공해줍니다.
- 데이터의 개수(count), 평균(mean), 표준편차(std), 최소값(min), 사분위수(25,50,75%), 최대값(max)을 포함합니다.

(2) .info()
- 데이터의 요약정보를 보여줍니다.
- 칼럼수, 칼럼명, 칼럼별 결측여부, 데이터타입, 메모리사용량 등을 확인할 수 있습니다.

(3) .head()
- 기본값으로 처음 5개의 행을 가져옵니다.
- 몇 개 행을 가져올지 임의로 지정할 수 있습니다. (head(3)을 사용시 처음 3개의 행을 가져옴)

(4) .tail()
- 기본값으로 마지막 5개의 행을 가져옵니다.
- head()와 마찬가지로 마지막 몇 개의 행을 가져올지 지정할 수 있습니다.

(5) .values()
- 데이터에 어떤 값들이 있는지 배열형태로 확인할 수 있습니다.
- 각각의 값들에 대해 확인할 때 유용합니다.

(6) .index()
- 인덱스의 이름과 인덱스의 값들을 확인할 수 있습니다.

(7) .columns()
- 데이터의 열의 이름을 확인할 수 있습니다.

(8) .shape
- 데이터의 행과 열의 개수를 확인할 수 있습니다.

5-2. Series 확인
시리즈 형태에서도 .describe()와 같은 함수를 사용할 수 있습니다.
시리즈에서 데이터를 확인 시에는 데이터셋에서 칼럼을 지정해준 후 함수를 적용해 줍니다.
시리즈에서 데이터를 확인하는 방법에 대해서는 예시를 통해서 보겠습니다.
(예 1) 키에 대한 통계량을 확인하고 싶을 때 (.describe() 함수 사용)

키에 대한 통계량을 요약하는 describe()를 사용하여 전체적인 통계량을 확인할 수 있습니다.
학생들의 키의 평균은 188cm이고, 중위수는 188cm, 최대값은 202cm이군요.
(예 2) 키가 큰사람 순서대로 3명을 출력하고 싶을 때 (nlargest() 함수 사용)
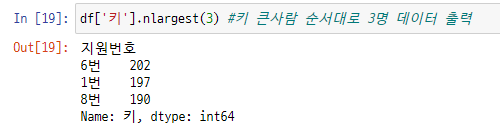
nlargest()함수를 사용하여 키가 큰 상위 3명의 학생을 출력할 수 있습니다.
좀 더 응용한다면 국어 점수가 가장 높은 상위 2명 학생을 출력하고 싶을때도 사용할 수 있겠네요.
그때의 코드는 df['국어'].nlargest(2)가 될 것입니다.
(예 3) 결측치를 제외한 데이터의 개수를 보고 싶을 때 (.count() 함수 사용)

위 데이터 셋에서 결측치가 존재하는 칼럼은 sw특기 칼럼입니다.
그 칼럼에 대해 결측치를 제외한 데이터의 개수를 보고 싶을 때에는 .count()를 사용하여 확인할 수 있습니다.
결측치를 포함한 데이터 개수를 보고싶을때는 .size()함수를 활용하면 됩니다.
(예 4) 열에서 존재하는 유니크한 값만 확인하고 싶을 때 (.unique() 함수 사용)

중복되지 않는 값들로 각 데이터를 보고 싶을 때 unique()함수를 사용합니다.
학교 칼럼에서 중복되지 않는 데이터를 보고싶다면 unique()를 사용해 존재하는 2개의 학교인 북산고, 능남고만 표시되게 할 수 있습니다.
추가로, .nunique()함수를 사용하면, 열에서 중복되지 않고, 존재하는 유니크한 값이 몇 개 있는지 확인할 수 있습니다.
이 경우 df['학교'].nunique()를 사용한다면 북산고, 능남고 2개의 학교로 구성되어 있으므로 2가 나오게 될 것입니다.
오늘은 데이터 확인하는방법에 대해 알아보았습니다.
해당 부분은 실제 데이터 분석 시 데이터 탐색단계에서 자주 쓰입니다.
주로 데이터 셋을 받았을 때 해당 데이터셋에 어떤 정보가 들어있는지 확인하고, 간단한 데이터를 확인하고자 할 때 많이 사용하게 됩니다. 즉 분석에 있어 제일 기초적인 부분이 될 수 있으므로 일부 관련된 코드를 암기하는 것이 좋을 것 같다는 생각을 했습니다.
다음 학습 내용 (Pandas #4)
06. 데이터 선택 (기본)
07. 데이터 선택 (loc)
08. 데이터 선택 (iloc)
감사합니다.
'Python > Pandas' 카테고리의 다른 글
| [파이썬 Pandas] 5. 데이터 필터링 (0) | 2022.08.11 |
|---|---|
| [파이썬 Pandas] 4. 데이터 선택 (0) | 2022.08.09 |
| [파이썬 Pandas] 2. 파일 저장 및 열기 (0) | 2022.08.04 |
| [파이썬 Pandas] 1. 데이터의 자료구조 (0) | 2022.08.02 |
| [파이썬 Pandas] Pandas 패키지 익히기 (0) | 2022.07.26 |




댓글