Today's Topic
- 일시적으로 사용하는 테이블을 만들기
- Used Function
- WITH구문
SQL문이 간단하다면 괜찮지만, 매우 복잡한 쿼리문일 경우 각 행별 쿼리를 보기가 힘들어집니다. 예를 들어 아주 많은 join을 해야 한다거나, row_number()와 같은 순위 함수를 중첩해서 많이 사용해야할 경우가 있습니다.
이럴 경우 with구문을 사용하면 임시적인 테이블에 이름을 새로 붙여 사용할 수 있기 때문에 효율이 올라갑니다.
물론, 그냥 이런 테이블을 물리 테이블로 저장하면 되지 왜 굳이 일시 테이블로 저장하느냐고 생각하실 수가 있을 것입니다. 하지만 일부 조직원 중에서는 create table문을 활용하여 실제 테이블을 생성할 수 있는 권한이 없는 경우가 있습니다. 이런 분들은 물리 테이블을 생성할 수 없기 때문에 db에서 뽑아낸 데이터를 분석하기가 매우 까다로울 수 있습니다.
이러한 경우를 해결하기 위해 사용하는 구문이 있는데, 바로 공통테이블 식, 즉 with구문입니다.
1. WITH 구문 (공통 테이블 식)
이번에는 with구문을 어떻게 사용할 수 있는지 살펴보겠습니다.
1-1) 쿼리식
WITH 생성하고자 하는 테이블이름 AS (SELECT 칼럼1, 칼럼2.... FROM 원래테이블명)
SELECT 칼럼1, 칼럼2..[*] FROM 생성한 테이블이름WITH를 먼저 적어주고, 자신이 임시로 생성하고자 하는 테이블 이름을 적어 줍니다.
그리고 AS를 사용하여 약간 서브쿼리와 비슷한 형태로 SELECT, FROM절을 활용해 원래 테이블에서 데이터를 추출합니다.
그리고 다음으로 SELECT, FROM절을 사용해 생성한 테이블에서 데이터를 뽑아냅니다.
1-2) 예제1. 테이블을 재사용하여 새로운 임시 테이블 만들기
다음과 같은 테이블이 있다고 하겠습니다. 테이블 이름은 'product'입니다.
해당 테이블을 재사용해 이름을 새로 붙이는 쿼리문을 작성해 보겠습니다.

with product_rank as (
select category_name, product_id, sales,
row_number() over(partition by category_name order by sales desc) as rank
from inlaid-lane-373607.sqlr202301.product
)
select * from product_rank;새로 만들 임시 테이블의 이름은 제가 product_rank라고 지정했고,
원래 데이터가 들어있는 물리 테이블인 product테이블에서 category_name, product_id, sales 칼럼을 추출하였습니다.
다만 쿼리문 3행에 카테고리별 순위를 추가한 칼럼이 있습니다.
이 칼럼은 물리 테이블에 들어가 있지 않은 칼럼이라 row_number()을 활용하여 고유한 순위를 부여했고, over()구문을 사용해 category_name별로 그룹화한 뒤 sales(판매량)칼럼을 내림차순으로 정렬한 값을 rank라는 별칭으로 부여한 것입니다.
그리고 4행에는 원래의 테이블에 대한 위치를 적어주었습니다.
해당 쿼리문을 실행하면 어떤 결과가 나올 수 있을까요?

위와 같이 rank칼럼이 추가되고, 테이블 이름이 product_rank으로 되었습니다. (물론 실제 테이블 이름이 수정된 것은 아닙니다. 임시 테이블이 만들어진 것이라 생각하시면 됩니다.)
또한 마지막 from절 쿼리를 작성할 때 굳이 길게 적지 않고 테이블명만 적어도 결과가 리턴되었습니다.
해당 쿼리를 실행시켜도 물리 테이블에는 저장되지 않았기 때문입니다.
1-3) 예제2. 재사용한 임시 테이블에서 고유한 값을 추출하기
이번에는 DISTINCT 구문을 사용하여 임시 테이블에는 어떤 순위값이 있는지 확인해 보겠습니다.다음 쿼리를 보시겠습니다.
with product_rank as (
select category_name, product_id, sales,
row_number() over(partition by category_name order by sales desc) as rank
from inlaid-lane-373607.sqlr202301.product
)
, rank_only as (select distinct rank from product_rank)
select * from rank_only
order by rank;이번에는 새로운 임시 테이블인 rank_only테이블을 만들었습니다. 거기에는 앞서 만든 임시 테이블인 product_rank테이블에서 뽑은 rank칼럼을 활용하는데, distinct구문을 추가하여 중복되지 않는 고유한 값만 출력되도록 하였습니다.그리고 목적은 어떤 순위로 구성되어 있는가를 확인하는 것이므로, 방금 했던 select * from 테이블명;을 사용하여 다음과 같은 결과를 확인할 수 있습니다.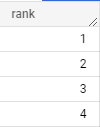
1-4) 예제3. 임시 테이블 만드는 방법을 활용해 새로운 새로운 테이블 만들기
마지막으로 기존 테이블을 재사용하는 방법이 아닌 아예 새로운 테이블을 만드는 예제를 보여드리겠습니다.
앞서 보여드린 예제와 쿼리의 형태는 비슷하지만, 새로운 테이블을 만드는 것이므로 값을 입력해 주어야 합니다.
작성 쿼리식은 다음과 같습니다.
with 만들 테이블 이름 as (
select '칼럼1의 값1' as 칼럼1 이름, '칼럼2의 값1' as 칼럼2 이름.....
union all
select '칼럼1의 값2' as 칼럼1 이름, '칼럼2의 값2' as 칼럼2 이름.....
union all
.
.
.
)
select * from 만든 테이블 이름;
복잡해 보이지만, 반복작업이 조금 많이 들어가서 실제로는 그렇게 복잡하지 않습니다.
예제를 통해 확인해 보겠습니다.
with busan_subway as(
select '다대포헤수욕장' as name, '1' as line_number, '101' as sta_number
union all
select '다대포향' as name, '1' as line_number, '102' as sta_number
union all
select '낫개' as name, '1' as line_number,'103' as sta_number
union all
select '장산' as name, '2' as line_number, '201' as sta_number
union all
select '중동' as name, '2' as line_number, '202' as sta_number
)
select * from busan_subway;부산의 도시철도 역명의 일부를 임시 테이블로 만드는 쿼리입니다.
with ~ as ( select절 다음에는 처음 칼럼, 두번째 칼럼, 세번째 칼럼에 들어갈 값과 이름)을 각각 적어준 것입니다.
쿼리를 읽는 대로 데이터가 들어간다고 생각하면 될 것 같습니다.
위 쿼리식을 실행하면 다음과 같은 결과가 나옵니다.

각 역들과 노선번호, 역번호가 해당 쿼리문에 맞게 추가된 것을 볼 수 있습니다.
이때까지 진행했던 일련의 작업들은 분석 담당자가 테이블을 생성할 권한이 없을 때 사용할 수 있는 임시 테이블을 만드는 것이므로
생성 권한이 있고, 자주 사용할 테이블이라면 물리 테이블을 생성하는 것이 성능면에서 더욱 좋습니다.
with구문을 사용하여 임시 테이블을 생성하고 재사용하는 방법은 이것으로 마무리하도록 하겠습니다.
감사합니다.
* 본 글은 데이터 분석을 위한 sql레시피 교재를 활용하여 작성되었습니다.
'SQL > Google Big Query' 카테고리의 다른 글
| [Big Query] 벤 다이어그램 분석 준비하기 (0) | 2023.02.14 |
|---|---|
| [Big Query] SQL을 활용해 Z차트 준비하기 (0) | 2023.02.08 |
| [빅쿼리 #10] 테이블 합치기 (UNION ALL, INNER JOIN, OUTER JOIN) (0) | 2023.02.01 |
| [빅쿼리 #9] 윈도우함수를 알아보자(2) (ROWS BETWEEN 구문, PARTITION BY 구문) (0) | 2023.01.31 |
| [빅쿼리 #8] 윈도우함수를 알아보자(1) (순위함수, 행의 값 조회 함수) (0) | 2023.01.30 |




댓글