# 본 내용은 " [나도코딩] - 파이썬 활용편(5) 데이터분석 및 시각화 " 강의를 듣고, 복습하고 공부한 내용을 다루었습니다.
오늘 포스팅할 내용은 다음과 같습니다.
Pandas #9. 그룹화 (groupby)
14. 그룹화
=>그룹화를 하여 다양한 통계량을 계산하고, 알맞은 데이터를 추출해내는 방법을 학습할 수 있습니다.
14. 그룹화
오늘은 pandas 데이터분석의 기초이자 꽃, 그룹화에 대해 학습해보겠습니다.
먼저 들어가기 전에 이 질문 먼저 던지고 가 보죠.
그룹화를 하는 이유가 뭔가요?
그룹화를 왜 할까요? 그냥 통계를 돌리면 되지 않을까요? 라고 생각하실 수도 있는데, 그렇게 처리한다면 어려운 사항이 많습니다.
햄버거집을 예로 들어보겠습니다.
햄버거집에는 불고기버거, 치킨버거, 치즈버거 등 다양한 종류가 있습니다. 또한 햄버거만 파는 것이 아닌, 음료수, 커피, 아이스크림 등등 다른 종류의 디저트도 판매하고 있지요.
우리가 전체 음식의 총 판매량의 평균을 계산하고 싶다면 그냥 .mean()을 써서 계산 하면 됩니다. 어렵지 않습니다.
하지만 햄버거 제품별 판매량을 계산하고 싶다면, 햄버거 제품별로 묶어서 판매량을 산출해야 합니다. 또한 월별, 요일별로 평균 판매량을 계산하고자 한다면 그거대로 묶어서 계산해야겠지요.
이때 필요한 것이 바로 그룹화, .groupby()함수입니다.
groupby()함수는 동일한 값을 가진 것 끼리 합쳐서 통계량을 산출할 때 유용하게 사용됩니다.
즉, 어떤 분석을 하고자 하면, 아주 간단한 분석이 아닌 이상 필연적으로 사용될 수 밖에 없는 것이 바로 그룹화이며,
이것이 데이터 분석의 시작이자 꽃이라고 표현하고자 합니다.
이제 본격적으로 그룹화에 대해 들어가 보도록 하겠습니다.
먼저 사용할 데이터를 import해 줍니다.

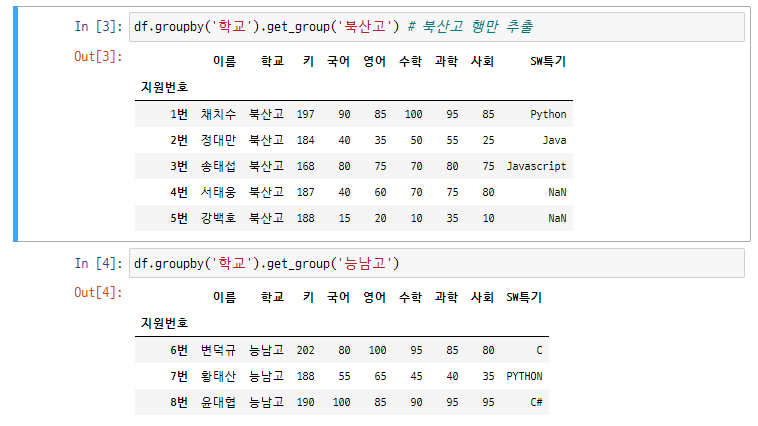
14-1. 그룹화 후 특정 행만 추출하기 (groupby()함수와 get_group()함수 활용)
- 학교별로 그룹화를 하고, get_group()함수를 사용해 출력될 행만 추출하겠습니다.
각 학교별로 어떤 학생들이 소속되어 있는지, 정보를 확인할 수 있습니다.
현재는 2개교밖애 없지만 이보다 많이, 10개 이상 학교가 있다면 좀 유용하게 쓰이겠지요.
14-2. 그룹화한 데이터로 다양한 값 산출하기
데이터프레임.groupby('그룹화할 칼럼').그룹화된 칼럼에 대한 적용할 함수명()
과 같이 적어주면 다양한 값을 산출할 수 있습니다.
.mean(): 평균값을 나타냅니다.
.size(): 데이터의 개수를 출력해 줍니다. (그룹의 크기정보)
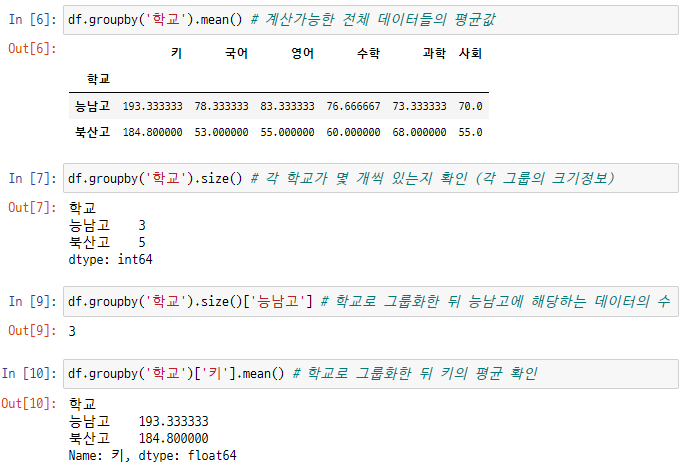
9행처럼, 학교로 묶고, 특정 학교에 해당하는 데이터의 개수는 몇 개 있는지 파악할 수 있으며,
특정 칼럼에 대한 평균만을 확인하고 싶을 경우에는 10행처럼 리스트 형태로 감싸주어 키의 평균만 출력되게 할 수 있습니다.
또한 아래와 같이 학교별 국영수 평균 성적을 한 눈에 확인해볼 수도 있습니다.

학년이라는 칼럼을 추가해서 조금 더 확장된 분석을 해 보겠습니다.

13행: 학년이라는 칼럼을 df데이터셋에 추가하였습니다.
14행: 학교와 학년별로 묶음으로써, 학교와 학년별 키, 각 과목의 평균을 계산할 수 있습니다.
15행: 학년별로 평균 키, 점수를 확인할 수 있습니다. (학교는 그룹화를 안했으므로 상관 없음)
평균 뿐만 아니라 .sum을 이용해 학교, 학년별 키의 합을 구할 수 있습니다.
키의 합을 구하는 것이 의미있는 것은 아니지만, 데이터셋 상에서 함수 연습을 위해 합계를 구해 보겠습니다.

14-3. sort_values()를 이용해 기준으로 할 칼럼을 정렬하기
여기서 새로운 함수가 하나 등장합니다.
바로 sort_values()함수인데요, 이 함수는 특정 열을 기준으로 정렬해주는 함수입니다.
그룹화를 했다면 제일 큰 순서대로 볼 필요가 있는 열을 기준으로 정렬해준다면 데이터를 직관적으로 확인해볼 수 있습니다.
아래 예시는 학년별로 묶은 뒤, 전체적인 평균을 산출하는데, 그 정렬 기준은 '키'를 기준으로 하겠다는 코드입니다.
여기서 sort_values()의 기본값은 오름차순 정렬이며, 속성으로 ascending=False를 적으면 키를 기준으로 내림차순 정렬 (키가 큰 순서대로 표시)할 수 있습니다.

14-4. count(), value_counts()함수 활용하기
마지막으로 count()함수와 value_counts()함수에 대해 살펴보겠습니다.
count()함수는 데이터의 개수를 세어주는 함수로, 각 칼럼에 데이터가 몇 개 있는지 출력해 줍니다. 단 null값은 세는 값에 포함되지 않습니다.
아래 데이터셋을 활용한 예시를 보시면, 각 학교별 이름과 sw특기의 개수를 출력했습니다.
하지만 원래라면 이름과 sw특기의 개수가 일치해야 하지만, 여기서 sw특기의 개수가 이름과 일치하지 않는다는 점을 볼 때, 이는 NaN값, 즉 결측치를 제외하고 세어 줍니다.

다음은 value_counts()함수입니다.
value_counts()역시 세어주는 함수입니다.
하지만 value_counts()는 카테고리별로 몇 개의 데이터가 있는지 세어 주는 함수라고 생각하면 됩니다.
아, 그러면 unique()함수와 비슷한 것이 아닌가라고 생각할 수 있습니다. 하지만 약간 다릅니다.
unique()는 유니크한(중복되지 않는) 값들을 직접 보여 주지만, value_counts()는 그 값의 개수를 보여준다는 점에서 차이가 있겠네요.
여기서 value_counts()를 사용하게 된다면 2가 나올 것입니다. (학교(북산고, 능남고)카테고리 개수는 2개이므로) [파이썬 Pandas] 3. 데이터 확인 에서 해당 함수에 대한 자세한 정보를 확인해 보세요.

아래 데이터는 학교별, 학년과 학년에 속하는 사람수를 가져온 것이며,
.loc()를 활용해 따로 특정 학교의 학년별 학생 수를 뽑아올 수도 있습니다.

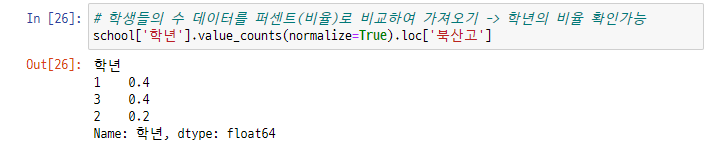
또한 아래와 같이 학생들의 수 데이터를 비율로 비교해서, 학년별 학생수의 비율을 표시할수도 있습니다.
school데이터셋의 학년 칼럼에서 북산고등학교의 학년별 학생수를 구하는데, normalize=True로 할 경우, 이것이 비율로 표시되는 옵션입니다. 즉, 결과값의 총 합이 1이 되겠지요.
이렇게 오늘은 Pandas의 최종인 그룹화에 대해 학습해 보았습니다.
Pandas는 분석을 위한 도구적인 측면이 많다고 생각합니다.
데이터를 분류하고, 결측값을 처리하고, 통계량을 산출하는것 까지 다양한 작업을 수행할 수 있었네요.
특히 이번에 학습한 그룹화는 대단히 중요한, 자주 쓰이는 개념이라 좀 더 깊게 학습해볼 필요도 있을 것 같습니다.
기초를 좀 다져놓으면 실제 분석을 할 때, 어떻게 코드를 읽어야 하고, 어떤 코드가 나에게 필요한 것인지 선별해낼 수 있기 때문에 좀 더 작업하기가 수월해지는 통찰력이 좀 생길 것이라 생각합니다.
Pandas에 대한 내용은 다음 퀴즈 풀이를 마지막으로 마무리할 예정입니다.
다음 학습 내용 (Pandas #10)
15 Pandas 문제풀이
감사합니다.
'Python > Pandas' 카테고리의 다른 글
| [파이썬 Pandas] 8. 함수 적용 (0) | 2022.08.23 |
|---|---|
| [파이썬 Pandas] 7. 데이터 수정 (0) | 2022.08.19 |
| [파이썬 Pandas] 6. 데이터 결측치 처리와 정렬방법 (0) | 2022.08.16 |
| [파이썬 Pandas] 5. 데이터 필터링 (0) | 2022.08.11 |
| [파이썬 Pandas] 4. 데이터 선택 (0) | 2022.08.09 |




댓글